[Python] 栈
栈抽象数据类型
栈是元素的有序集合,添加操作与移除操作都发生在其顶端。栈的操作顺序是 LIFO(last-in first-out),即后进先出。它支持以下操作:
Stack()创建一个空栈。它不需要参数,且会返回一个空栈。push(item)将一个元素添加到栈的顶端。它需要一个参数 item,且无返回值。pop()将栈顶端的元素移除。它不需要参数,但会返回顶端的元素,并且修改栈的内容。peek()返回栈顶端的元素,但是并不移除该元素。它不需要参数,也不会修改栈的内容。isEmpty()检查栈是否为空。它不需要参数,且会返回一个布尔值。size()返回栈中元素的数目。它不需要参数,且会返回一个整数。
栈操作示例
| 操作 | 栈内容 | 返回值 |
|---|---|---|
s.isEmpty() | [] | True |
s.push(4) | [4] | |
s.push('dog') | [4, 'dog'] | |
s.peek() | [4, 'dog'] | 'dog' |
s.push(True) | [4, 'dog', True] | |
s.size() | [4, 'dog', True] | 3 |
s.isEmpty() | [4, 'dog', True] | False |
s.push(8.4) | [4, 'dog', True, 8.4] | |
s.pop() | [4, 'dog', True] | 8.4 |
s.pop() | [4, 'dog'] | True |
s.size() | [4, 'dog'] | 2 |
用 Python 实现栈
因为栈是元素的集合,所以完全可以利用 Python 提供的强大、简单的原生集合来实现。这里,我们将使用列表。
方法一
class Stack:
def __init__(self):
self.items = []
def isEmpty(self):
return self.items == []
def push(self, item):
self.items.append(item)
def pop(self):
return self.items.pop()
def peek(self):
return self.items[len(self.items)-1]
def size(self):
return len(self.items)假设列表的尾部是栈的顶端。当栈增长时(即进行
push操作),新的元素会被添加到列表的尾部。
方法二
class Stack:
def __init__(self):
self.items = []
def isEmpty(self):
return self.items == []
def push(self, item):
self.items.insert(0, item)
def pop(self):
return self.items.pop(0)
def peek(self):
return self.items[0]
def size(self):
return len(self.items)假设列表的头部是栈的顶端。在这种情况下,便无法直接使用
pop方法和append方法,而必须要用pop方法和insert方法显式地访问下标为0的元素,即列表中的第1个元素。
用栈匹配括号
编写一个算法,它从左到右读取一个括号串,然后判断其中的括号是否匹配。
为了解决这个问题,需要注意到:
- 当从左到右处理括号时,最右边的无匹配左括号必须与接下来遇到的第一个右括号相匹配。
- 在第一个位置的左括号可能要等到处理至最后一个位置的右括号时才能完成匹配。
- 相匹配的右括号与左括号出现的顺序相反。
这一规律暗示着能够运用栈来解决括号匹配问题。
from pythonds.basic import Stack
def parChecker(symbolString):
s = Stack()
balanced = True
index = 0
while index < len(symbolString) and balanced:
symbol = symbolString[index]
if symbol == "(":
s.push(symbol)
else:
if s.isEmpty():
balanced = False
else:
s.pop()
index = index + 1
if balanced and s.isEmpty():
return True
else:
return False用栈匹配符号(普通情况)
符号匹配是许多编程语言中的常见问题,括号匹配问题只是一个特例。匹配符号是指正确地匹配和嵌套左右对应的符号。要处理新类型的符号,可以扩展上面的括号匹配检测器。
唯一的区别在于,当出现右符号时,必须检测其类型是否与栈顶的左符号类型相匹配。如果两个符号不匹配,那么整个符号串也就不匹配。同样,如果整个符号串处理完成并且栈是空的,那么就说明所有符号正确匹配。
from pythonds.basic import Stack
def parChecker(symbolString):
s = Stack()
balanced = True
index = 0
while index < len(symbolString) and balanced:
symbol = symbolString[index]
if symbol in "([{":
s.push(symbol)
else:
if s.isEmpty():
balanced = False
else:
top = s.pop()
if not matches(top, symbol):
balanced = False
index = index + 1
if balanced and s.isEmpty():
return True
else:
return False
def matches(open, close):
opens = "([{"
closers = ")]}"
return opens.index(open) == closers.index(close)用栈将十进制数转换成二进制数
“除以 2”算法:
假设待处理的整数大于 0。它用一个简单的循环不停地将十进制数除以 2,并且记录余数。第一次除以 2 的结果能够用于区分偶数和奇数。如果是偶数,则余数为 0,因此个位上的数字为 0;如果是奇数,则余数为 1,因此个位上的数字为 1。可以将要构建的二进制数看成一系列数字;计算出的第一个余数是最后一位。如下图所示,

from pythonds.basic import Stack
def divideBy2(decNumber):
remstack = Stack()
while decNumber > 0:
rem = decNumber % 2
remstack.push(rem)
decNumber = decNumber // 2
binString = ""
while not remstack.isEmpty():
binString = binString + str(remstack.pop())
return binString用栈将十进制数转换成任意进制数
可以将 divideBy2 函数修改成接受一个十进制数以及希望转换的进制基数,“除以 2”则变
成“除以基数”。
以 2~10 为基数时,最多只需要 10 个数字,因此 0~9 这 10 个整数够用。当基数超过 10 时,就会遇到问题。不能再直接使用余数,这是因为余数本身就是两位的十进制数。
解决方法是添加一些字母字符到数字中。例如,十六进制使用 10 个数字以及前 6 个字母来代表 16 位数字。
from pythonds.basic import Stack
def baseConverter(decNumber, base):
digits = "0123456789ABCDEF"
remstack = Stack()
while decNumber > 0:
rem = decNumber % base
remstack.push(rem)
decNumber = decNumber // base
newString = ""
while not remstack.isEmpty():
newString = newString + digits[remstack.pop()]
return newString前序、中序和后序表达式
中序、前序与后序表达式示例:
| 中序表达式 | 前序表达式 | 后序表达式 |
|---|---|---|
A + B | + A B | A B + |
A + B * C | + A * B C | A B C * + |
(A + B) * C | * + A B C | A B + C * |
A + B * C + D | + + A * B C D | A B C * + D + |
(A + B) * (C + D) | * + A B + C D | A B + C D + * |
A * B + C * D | + * A B * C D | A B * C D * + |
A + B + C + D | + + + A B C D | A B + C + D + |
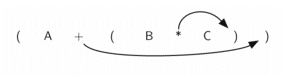
如上图所示,观察子表达式 (B * C) 的右括号。如果将乘号移到右括号所在的位置,并且去掉左括号,就会得到 B C *,这实际上是将该子表达式转换成了对应的后序表达式。如果把加号也移到对应的右括号所在的位置,并且去掉对应的左括号,就能得到完整的后序表达式。
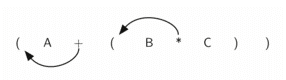
同理,如果将运算符移到左括号所在的位置,并且去掉对应的右括号,就能得到前序表达式。
因此,若要将任意复杂的中序表达式转换成前序表达式或后序表达式,可以先将其写作完全括号表达式,然后将括号内的运算符移到左括号处(前序表达式)或者右括号处(后序表达式)。
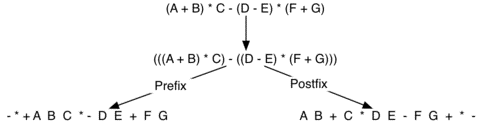
下面来看一个更复杂的表达式:(A + B) * C − (D − E) * (F + G)。下图展示了将其转换成前序表达式和后序表达式的过程。
用栈实现从中序到后序的通用转换法
当遇到左括号时,需要将其保存,以表示接下来会遇到高优先级的运算符;那个运算符需要等到对应的右括号出现才能确定其位置;当右括号出现时,便可以将运算符从栈中取出来。
在从左往右扫描中序表达式时,我们利用栈来保存运算符。这样做可以提供反转特性。栈的顶端永远是最新添加的运算符。每当遇到一个新的运算符时,都需要对比它与栈中运算符的优先级。
假设中序表达式是一个以空格分隔的标记串。其中,运算符标记有 *、 /、 + 和 −,括号标记有 ( 和 ),操作数标记有 A、 B、 C 等。下面的步骤会生成一个后序标记串。
- 创建用于保存运算符的空栈
opstack,以及一个用于保存结果的空列表。 - 使用字符串方法
split将输入的中序表达式转换成一个列表。 - 从左往右扫描这个标记列表。
- 如果标记是操作数,将其添加到结果列表的末尾。
- 如果标记是左括号,将其压入
opstack栈中。 - 如果标记是右括号,反复从
opstack栈中移除元素,直到移除对应的左括号。将从栈中
取出的每一个运算符都添加到结果列表的末尾。 - 如果标记是运算符,将其压入
opstack栈中。但是,在这之前,需要先从栈中取出优先
级更高或相同的运算符,并将它们添加到结果列表的末尾。
- 当处理完输入表达式以后,检查
opstack。将其中所有残留的运算符全部添加到结果列
表的末尾。
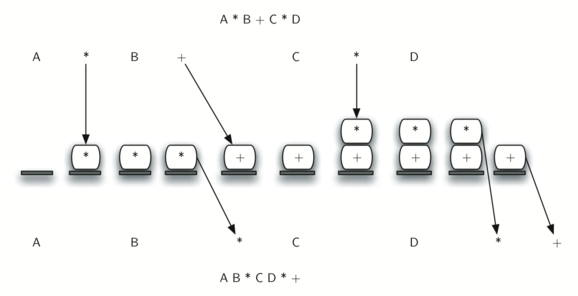
上图展示了利用上述算法转换 A * B + C * D 的过程。注意,第一个 * 在处理至 + 时被移出栈。由于乘号的优先级高于加号,因此当第二个 * 出现时, + 仍然留在栈中。在中序表达式的最后,进行了两次出栈操作,用于移除两个运算符,并将 + 放在后序表达式的末尾。
from pythonds.basic import Stack
import string
def infixToPostfix(infixexpr):
prec = {}
prec["*"] = 3
prec["/"] = 3
prec["+"] = 2
prec["-"] = 2
prec["("] = 1
opStack = Stack()
postfixList = []
tokenList = infixexpr.split()
for token in tokenList:
if token in string.ascii_uppercase:
postfixList.append(token)
elif token == '(':
opStack.push(token)
elif token == ')':
topToken = opStack.pop()
while topToken != '(':
postfixList.append(topToken)
topToken = opStack.pop()
else:
while (not opStack.isEmpty()) and \
(prec[opStack.peek()] >= prec[token]):
postfixList.append(opStack.pop())
opStack.push(token)
while not opStack.isEmpty():
postfixList.append(opStack.pop())
return " ".join(postfixList)我们使用一个叫作 prec 的字典来保存运算符的优先级值。该字典把每一个运算符都映射成一个整数。通过比较对应的整数,可以确定运算符的优先级(本例随意地使用了 3、 2、 1)。左括号的优先级值最小。这样一来,任何与左括号比较的运算符都会被压入栈中。我们也将导入 string 模块,它包含一系列预定义变量。本例使用一个包含所有大写字母的字符串string.ascii_uppercase来代表所有可能出现的操作数。
用栈计算后序表达式
当扫描后序表达式时,需要保存操作数,而不是运算符。即,当遇到一个运算符时,需要用离它最近的两个操作数来计算。
假设后序表达式是一个以空格分隔的标记串。其中,运算符标记有 *、 /、 + 和 −,操作数标记是一位的整数值。结果是一个整数。
- 创建空栈
operandStack。 - 使用字符串方法
split将输入的后序表达式转换成一个列表。 - 从左往右扫描这个标记列表。
- 如果标记是操作数,将其转换成整数并且压入
operandStack栈中。 - 如果标记是运算符,从
operandStack栈中取出两个操作数。第一次取出右操作数,第二次取出左操作数。进行相应的算术运算,然后将运算结果压入operandStack栈中。
- 如果标记是操作数,将其转换成整数并且压入
- 当处理完输入表达式时,栈中的值就是结果。将其从栈中返回。
from pythonds.basic import Stack
def postfixEval(postfixExpr):
operandStack = Stack()
tokenList = postfixExpr.split()
for token in tokenList:
if token in "0123456789":
operandStack.push(int(token))
else:
operand2 = operandStack.pop()
operand1 = operandStack.pop()
result = doMath(token, operand1, operand2)
operandStack.push(result)
return operandStack.pop()
def doMath(op, op1, op2):
if op == "*":
return op1 * op2
elif op == "/":
return op1 / op2
elif op == "+":
return op1 + op2
else:
return op1 - op2为了方便运算,我们定义了辅助函数 doMath。它接受一个运算符和两个操作数,并进行相应的运算。
注意:在后序表达式的转换和计算中,我们都假设输入表达式没有错误。
本作品采用 知识共享署名-相同方式共享 4.0 国际许可协议 进行许可。
评论已关闭